

요즘 생성형 AI나 대규모 모델 이야기만 나오면, 뒤에 꼭 붙는 이름이 바로 데이터센터용 가속기예요. 뉴스나 기사에서는 엄청난 연산량과 숫자들만 쏟아져 나오는데, 막상 실제 서버를 구성하려는 입장에서는 이게 어느 정도 급이고, 전력이랑 냉각은 얼마나 잡아야 하는지 감이 잘 안 오더라고요. 특히 여러 장을 묶어서 클러스터를 꾸리려다 보면, GPU 가격보다 랙 설계랑 전기 용량이 더 무섭게 느껴지는 경우도 있어요. 그래서 오늘은 고성능 AI 가속기를 대표하는 한 모델을 기준으로, 어떤 구조와 특징을 갖고 있고 실무에서 어떤 관점으로 봐야 덜 헤매는지 천천히 풀어볼게요.

🧠 호퍼 아키텍처와 FP8, 숫자보다 중요한 핵심 포인트
엔비디아의 호퍼 아키텍처는 텐서 코어 세대가 한 번 더 올라가면서, 특히 트랜스포머 모델에 최적화된 구조로 설계되어 있어요. 80GB급 HBM3 메모리와 수 TB/s대 대역폭, NVLink·NVSwitch 기반 확장 구조 덕분에, 수십억~수백억 파라미터 모델을 여러 장에 나눠 올려도 데이터가 빠르게 오갈 수 있게 설계된 셈이죠. 이 라인업 중에서도 NVIDIAH100은 FP8 지원 트랜스포머 엔진 덕분에 이전 세대 대비 같은 전력에서 훈련 속도를 크게 당겨 놓은 게 가장 눈에 띄는 포인트예요.
FP8이라는 낮은 정밀도를 쓰면 정확도가 떨어질까 걱정되지만, 실제로는 레이어별 스케일링과 혼합 정밀도를 섞어서 쓰기 때문에 대부분의 LLM·비전 트랜스포머에서는 성능 손실 없이 속도를 끌어올리는 데 초점이 맞춰져 있어요. 덕분에 같은 랙에 들어가는 카드 수가 같더라도, 학습량과 처리 가능한 데이터셋 규모가 체감상 한 세대 위로 올라간 느낌을 받기 쉽죠. 이런 구조를 이해해 두면 단순 TFLOPS 숫자보다, 어떤 워크로드에서 강점을 보이는지 판단하는 데 도움이 돼요.
또 하나 중요한 게 MIG 기능이에요. 한 장의 GPU를 여러 개의 작은 인스턴스로 쪼개서, 학습·추론·서빙을 섞어 쓸 수 있는 구조라 멀티 테넌트 환경에서 자원 활용률을 끌어올리기 좋거든요. 이 기능을 적극적으로 활용하면, 대규모 학습이 없는 시간대에 작은 추론 작업들을 끼워 넣는 식으로, GPU를 놀리지 않고 꽉 채워 쓸 수 있는 여지가 훨씬 넓어져요.

🚀 학습·추론 성능, A100과 비교해서 체감 차이
많은 분들이 제일 먼저 궁금해하는 건 “기존 A100 대비 얼마나 빠르냐”예요. 단순 정밀도 기준으로 보면 TFLOPS 숫자도 많이 올라갔지만, 실제 체감은 트랜스포머 엔진과 FP8 덕분에 더 크게 느껴져요. GPT-3급 모델 학습 기준으로 공개된 수치를 보면, 같은 수의 카드로도 학습 시간이 수배 단위로 줄어드는 경우가 많아서, 데이터센터 입장에서는 전기·시간 비용을 함께 줄이는 효과가 생겨요. 결국 같은 예산으로 훨씬 많은 실험을 돌릴 수 있다는 의미라, 연구·서비스 양쪽에 모두 메리트가 있죠.
추론 쪽에서는 배치 처리량과 지연 시간 둘 다 중요해요. 대규모 LLM을 서비스할 때는 초당 토큰 처리량이 곧 서버 장비 수와 직결되기 때문에, 카드 한 장당 얼마나 많은 요청을 감당할 수 있는지가 핵심이거든요. 호퍼 세대는 메모리 대역폭과 캐시 구조를 크게 끌어올리면서, 같은 파라미터 수를 가진 모델이라도 더 빠르게 토큰을 밀어낼 수 있도록 설계됐어요. 특히 상시 서비스 중인 챗봇이나 검색 연동 LLM에서는 이 차이가 장비 수와 비용으로 바로 드러나게 돼요.
재미있는 건, 기존에 A100 기준으로 짜놨던 클러스터를 그대로 두고 카드만 교체했을 때예요. 전력과 냉각 조건이 허용된다면, 같은 랙 구성으로도 처리 가능한 모델 크기와 동시 접속자 수가 확 늘어나기 때문에, 인프라 팀 입장에서는 “랙 추가 없이 성능 업그레이드”라는 꽤 달콤한 시나리오가 나와요. 그래서 신규 구축뿐 아니라 기존 센터 리프레시 용도로도 이 세대가 많이 거론되는 거예요. 이때 어떤 모델을 어떤 비율로 학습·추론에 배분할지 설계하는 게 관건이에요. 여기에서 적절히 NVIDIAH100 카드 수와 노드 구성을 맞추면, 단위 전력당 처리량을 꽤 공격적으로 끌어올릴 수 있어요.
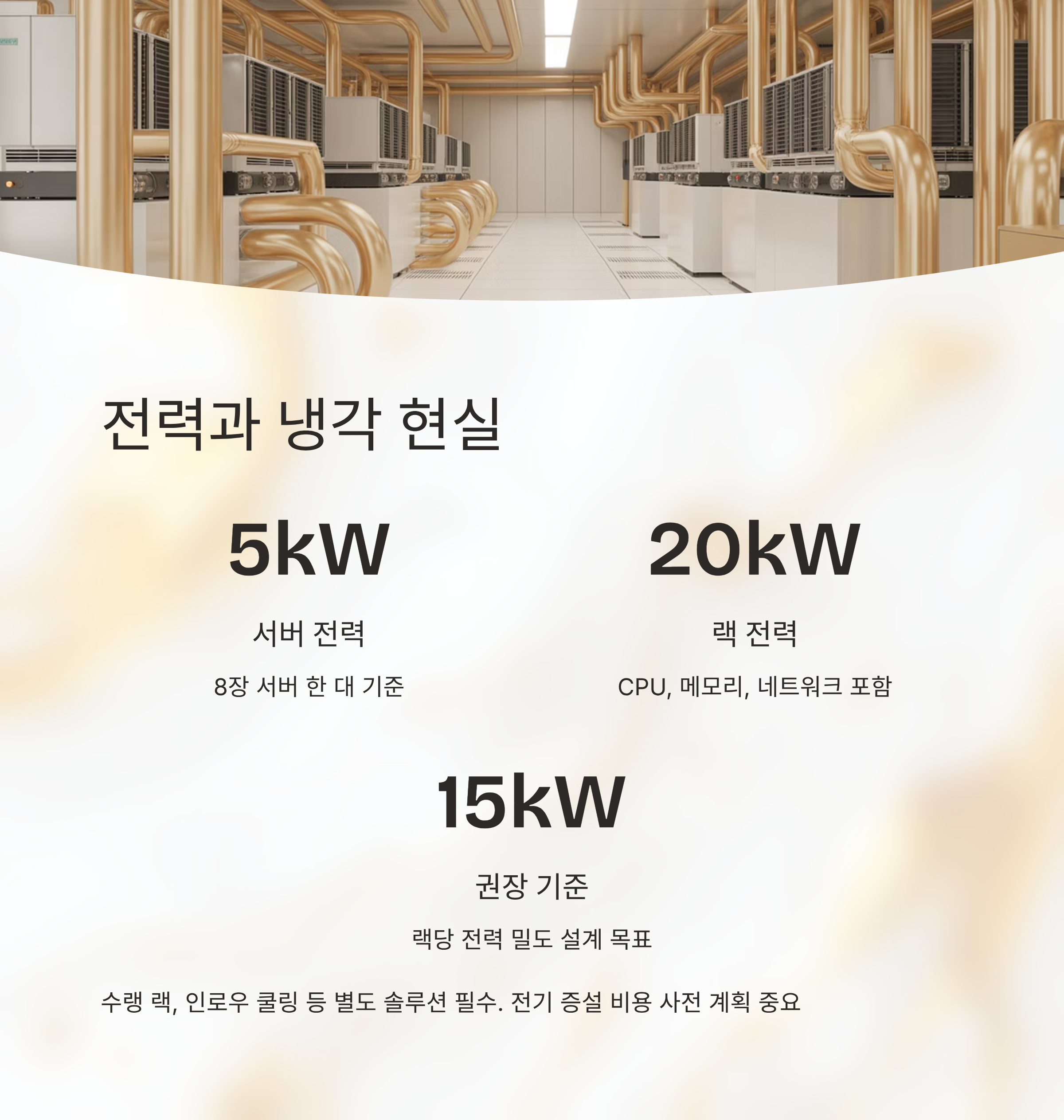
💡 전력·냉각·랙 설계, 숫자부터 현실적으로 계산하기
이 급 GPU를 도입할 때 가장 현실적인 고민은 결국 전력과 냉각이에요. SXM 모듈 기준으로 카드 한 장이 수백 와트를 넘기다 보니, 8장짜리 서버 한 대만으로도 5kW에 가까운 전력을 잡아야 하는 경우가 많거든요. 여기에 CPU, 메모리, 스토리지, 네트워크까지 합치면 랙 단위로 20kW 이상이 필요할 수도 있어서, 기존 데이터센터 인프라로는 감당이 안 되는 상황이 꽤 자주 나와요. 그래서 처음부터 전기·냉각 담당 팀과 같이 설계 회의를 하는 게 거의 필수에 가깝다고 보시면 돼요.
공랭만으로는 버거운 환경이라면 수랭 랙이나 인로우 쿨링 같은 별도 솔루션을 고민해야 하는데, 이 부분에서 예산이 크게 갈려요. 단순히 카드 가격만 보고 계획을 세웠다가, 냉각 설비와 전기 증설 비용에서 충격을 받는 경우가 진짜 많거든요. 반대로 처음부터 목표 전력 밀도를 정해놓고, 그 안에서 몇 장까지 넣을지 계산해 들어가면 설계가 훨씬 깔끔해져요. 예를 들어 랙당 15kW를 기준으로 잡고, 여기에 들어갈 서버 수와 카드 수를 역산하는 방식이죠. 이런 식으로 계획을 짜면, 자연스럽게 한 노드 안에 들어갈 NVIDIAH100 수량과 NVLink 토폴로지도 같이 정리되기 쉬워요.
또 하나 중요한 건 전기요금 구조예요. 학습 클러스터는 24시간 풀로드에 가까운 상태로 돌아가는 경우가 많아서, 단위 전력당 성능이 곧 월간 고정비와 직결돼요. 최신 세대로 넘어갈수록 와트당 처리량이 좋아지는 만큼, 초기 투자와 운영비 절감을 같이 놓고 비교해 보는 게 필요해요. 단순히 카드 가격만 비교하기보다, “같은 예산·같은 전력에서 몇 토큰을 더 처리할 수 있느냐”를 기준으로 계산해 보면 의사결정이 훨씬 명확해져요.

🧩 NVLink·NVSwitch 토폴로지, 클러스터 설계의 핵심
대규모 모델을 한 번에 올리려면, GPU 한 장의 성능보다 여러 장을 어떻게 묶을지가 더 중요해요. NVLink와 NVSwitch를 통해 카드 간 대역폭을 수백 GB/s 단위로 연결해 주면, 모델 파이프라인 병렬화나 텐서 병렬화를 쓸 때 통신 병목이 크게 줄어들거든요. 특히 8장 단위 서버를 여러 대 묶는 DGX·HGX 계열 구성을 쓰면, GPU 간 통신 구조를 비교적 단순한 패턴으로 가져갈 수 있어서 소프트웨어 팀 입장에서도 다루기가 수월해요. 이런 환경에서 NVIDIAH100의 메모리 대역폭과 NVLink 성능이 제대로 효과를 발휘해요.
토폴로지를 짤 때는 어떤 병렬화 전략을 쓸지도 같이 고민해야 해요. 데이터 병렬만으로 커버하기 어려운 초거대 모델이라면, 텐서·파이프라인 병렬을 섞어 쓰는 구조가 필수인데, 이때 GPU 간 통신 패턴이 복잡해지거든요. 토폴로지가 잘못 짜여 있으면, 정작 연산은 남았는데 통신 대기 때문에 성능이 반 토막 나는 상황이 나올 수 있어요. 그래서 초기 설계 단계에서부터 프레임워크 팀과 인프라 팀이 같이 앉아서, 실제 모델 구조를 기준으로 노드와 링크 구성을 정리하는 게 중요해요.
멀티 노드로 확장할 때는 인피니밴드나 고속 이더넷 구조까지 함께 따라와야 해요. GPU 내부·노드 내부·노드 간 대역폭의 균형을 맞춰놓지 않으면, 특정 구간만 막혀서 전체 처리량이 줄어드는 병목이 생기거든요. 결국 클러스터 설계는 “어디까지를 GPU가 책임지고, 어디서부터는 네트워크가 받쳐줘야 하는가”를 정리하는 과정이라, 실제 서비스할 모델과 성장 계획을 기준으로 단계별 확장 전략을 세워두면 나중에 훨씬 덜 힘들어요.

🔧 프레임워크·소프트웨어 스택, 생각보다 중요한 호환성
하드웨어 스펙이 아무리 좋아도, 소프트웨어 스택이 제대로 받쳐주지 않으면 성능이 반도 안 나오는 경우가 많아요. CUDA·cuDNN·TensorRT 같은 기본 라이브러리 버전은 물론이고, 파이토치·텐서플로·JAX 같은 프레임워크에서 호퍼 세대 최적화를 지원하는지 확인하는 게 중요해요. 특히 혼합 정밀도와 텐서 패럴렐, 파이프라인 패럴렐 관련 기능은 버전 차이로 동작이 살짝씩 달라질 수 있어서, 프로토타입을 구축할 때부터 버전 전략을 정해두는 게 좋아요.
대부분의 메이저 프레임워크와 분산 학습 라이브러리는 이미 호퍼 세대에 맞춰 최적화가 진행되어 있지만, 내부에서 커스텀 CUDA 커널을 많이 쓰는 팀이라면 별도의 검증 과정이 필요해요. 커널 컴파일 옵션과 레지스터 사용량, 메모리 접근 패턴을 다시 점검해야 최적의 성능을 뽑을 수 있거든요. 이 과정에서 프로파일링 도구를 적극적으로 쓰면 병목 구간을 빨리 찾을 수 있고, 어떤 부분을 리팩터링해야 할지도 금방 보이기 시작해요. 이런 준비를 마친 뒤에야 비로소 NVIDIAH100의 잠재력을 코드 레벨에서 끝까지 끌어낼 수 있어요.
운영 관점에서는 모니터링과 오토스케일링도 중요해요. GPU 사용률, 메모리 점유, 온도, 에러 로그를 한 번에 볼 수 있는 대시보드를 구축해 두면, 어느 시점에 노드를 더 늘려야 하는지, 어떤 작업이 자원을 과하게 쓰고 있는지 빠르게 파악할 수 있어요. 이렇게 소프트웨어와 운영 체계를 함께 정비해 두면, 클러스터가 커져도 “어디가 병목인지 알 수 없는 상황”에 빠질 확률이 많이 줄어들어요.

📊 도입 시점과 예산, 우리에게 정말 필요한 규모인지
고성능 GPU 소식을 듣다 보면, 당장이라도 최고 사양 장비를 들여와야 할 것 같은 기분이 들기 쉬워요. 하지만 실제로는 모델 규모와 서비스 단계에 따라 필요한 리소스가 크게 달라져서, 먼저 우리 팀이 어떤 워크로드를 얼마나 자주 돌릴지부터 정리하는 게 순서예요. 실험 위주의 연구 단계인지, 상시 트래픽을 받는 서비스 단계인지에 따라, 필요한 카드 수와 클러스터 구조가 완전히 달라지거든요. 간단히 말해 “지금 당장 꼭 필요한 최소 사양”과 “1~2년 뒤 확장 목표”를 따로 적어보는 것만으로도 그림이 많이 선명해져요.
예산 측면에서는 초기 장비 비용뿐 아니라, 3년 정도의 전기·냉각·운영 인력 비용을 함께 묶어서 보는 게 좋아요. 그런 다음, 같은 기간 동안 예상되는 모델 학습 횟수와 추론 트래픽을 넣어 “토큰당 비용”을 계산해 보면, 어느 지점에서 이 세대 장비가 경제성을 갖는지 감이 잡혀요. 이 과정에서 자연스럽게 NVIDIAH100급 장비를 도입해야 하는 시점과, 아직은 클라우드나 한 단계 낮은 사양으로 버텨도 되는 시점이 구분되기 시작해요.
직접 장비를 들여오기 부담된다면, 초반에는 클라우드나 코로케이션 기반 GPU 임대를 활용해 워크로드 특성을 먼저 파악해 보는 것도 방법이에요. 그 결과를 바탕으로 “이 정도면 자체 클러스터를 꾸리는 게 더 이득이겠다”는 확신이 설 때, 온프레미스 도입을 검토해도 늦지 않거든요. 결국 중요한 건 남들이 어떤 사양을 쓰는지가 아니라, 우리 서비스와 연구에 맞는 적절한 타이밍과 규모를 찾는 거예요.

데이터센터용 GPU 이야기를 듣다 보면 숫자와 전문용어에 먼저 압도되기 쉬운데, 막상 하나씩 뜯어보면 결국 “주어진 전력과 공간 안에서 얼마나 많은 일을 꾸준히 시킬 수 있느냐”로 정리가 되더라고요. 오늘 정리한 내용들이 이런 고성능 장비를 조금 더 현실적인 눈높이에서 바라보는 데 작은 기준이 되었으면 해요. 나에게 필요한 건 최고 사양 그 자체가 아니라, 우리 팀이 몇 년 동안 안심하고 돌릴 수 있는 안정적인 조합이라는 점만 기억해 두시면 선택이 훨씬 수월해질 거예요. 천천히 숫자를 정리해 보시다 보면, 자연스럽게 우리에게 맞는 규모와 시점이 보일 거라고 생각해요.

💡 이런 질문 많으시더라고요
Q. 아직 A100 클러스터를 쓰고 있는데, 바로 교체할 만큼 차이가 클까요?
A. 워크로드에 따라 다르지만, 트랜스포머 기반 모델 학습·추론에서는 세대 차이가 확실히 큰 편이라, 향후 2~3년 이상 AI를 적극 활용할 계획이라면 단계적 교체를 검토해 볼 만해요.
Q. 전력과 냉각 인프라가 충분하지 않은 중소 규모 센터에서도 운용이 가능할까요?
A. 랙당 전력 밀도를 현실적으로 계산해 보고, 카드 수를 줄이는 대신 효율을 높이는 방향으로 설계하면 운용 자체는 가능하지만, 장비 수를 빠르게 늘리기는 어려울 수 있어요.
Q. 학습과 추론 중 어떤 용도에 더 적합하다고 봐야 할까요?
A. 둘 다 강점을 가지고 있지만, 특히 대규모 LLM 학습과 고성능 추론 서비스를 동시에 운영해야 하는 환경에서 장점을 가장 크게 체감하실 거예요.
Q. 처음 구축할 때는 온프레미스와 클라우드 중 어느 쪽이 더 현실적일까요?
A. 초반에는 클라우드로 워크로드 특성과 규모를 파악해 보고, 일정 수준 이상 사용량이 고정되면 온프레미스 도입을 검토하는 식의 하이브리드 전략이 많이 쓰여요.
Q. 이런 고성능 GPU를 꼭 써야 하는 최소 규모의 모델이나 서비스 기준이 있을까요?
A. 수십억 파라미터 이하 모델이나 트래픽이 크지 않은 서비스라면 한 단계 낮은 사양으로도 충분할 수 있어서, 현재와 1~2년 뒤 목표 모델 규모를 먼저 정리해 보시는 걸 권장드려요.

'윈도우이야기' 카테고리의 다른 글
| I713700KF 13세대 i7 게이밍 성능 발열 전력 체감 총정리 실사용 (0) | 2025.12.28 |
|---|---|
| 삼성포터블SSDT7 외장SSD 속도 보안 백업 활용법 실사용 총정리 (2) | 2025.12.27 |
| LS27C312EAKXKR 27인치 IPS FHD 사무용 모니터 특징 (1) | 2025.12.25 |
| I513600K 13세대 i5 게이밍 성능과 전력 발열 균형 체크 (0) | 2025.12.24 |
| I57400 7세대 i5 사무용 게이밍 겸용 업그레이드 체감 정리 (0) | 2025.12.23 |



